Editors' Introduction

Editors' Introduction |
|
|
Jyrki Kivinen,
Csaba Szepesvári,
Esko Ukkonen,
and
Thomas Zeugmann
|
|
The ALT-conference series is focused on studies of learning
from an algorithmic and mathematical perspective. During the last decades
various models of learning emerged and a main goal is to investigate how
various learning problems can be formulated and solved in some of the
abstract models.
The general study of scenarios in which computer programs learn from information provided to them involves a considerable interaction between different branches of mathematics and computer science such as analysis, statistics, probability theory, combinatorics, theory of computation, Kolmogorov complexity, and analysis of algorithms. There are also close connections to the more empirical oriented disciplines of machine learning. This wide variety is also nicely reflected in the papers contained in this volume. In the following, we shall introduce the five invited lectures and the regular contributions in some more detail.
Yoshua Bengio (Université de Montréal) received his PhD from McGill University in 1991. His work covers a variety of topics in machine learning and neural networks. Much of his recent work has focused on deep architectures, which were also the topic of his invited presentation On the Expressive Power of Deep Architectures (joint work with Olivier Delalleau). Using representations with several layers allows building higher-level abstractions on top of some simple underlying structure, which might be needed to solve challenging AI problems. For a long time the study of deep architectures was discouraged by the lack of good learning algorithms for them, but recently there have been some striking successes that have brought the topic back into mainstream. The invited presentation gave theoretical and practical motivations for deep architectures, surveyed some of the successful algorithms and considered ideas for further challenges. Jorma Rissanen (Helsinki Institute for Information Technology) received his PhD from Helsinki University of Technology in 1965. During his long career he has made several highly influential contributions to information theory and its applications. He received the IBM Outstanding Innovation Award in 1988, the IEEE Richard W. Hamming Medal in 1993, and the Kolmogorov Medal in 2006. Furthermore, his honors include receiving in 2009 the Claude E. Shannon Award for his work in developing arithmetic coding. Within the machine learning community he is perhaps best known for introducing and developing the Minimum Description Length principle. His invited talk Optimal Estimation presented new information-theoretic methods for estimating parameters, their number and structure, with results about their optimality properties. Eyke Hüllermeier (Universität Marburg) received his PhD in 1997 from the Computer Science Department of the University of Paderborn, and his Habilitation degree in 2002 from the same university. From 1998 to 2000, he spend two years as a Marie Curie fellow at the Institut de Recherche en Informatique de Toulouse. Currently, he is also the head of the IEEE/CIS ETTC Task Force on Machine Learning. Johannes Fürnkranz (Technical University of Darmstadt) obtained his PhD in 1994, and the Habilitation degree in 2001 both from the Technical University of Vienna. In 2002 he received a prestigious APART stipend of the Austrian Academy of Sciences. His main research interest is machine learning. He also received an ``Outstanding Editor Award'' of the Machine Learning journal. In their invited talk Learning from Label Preferences Eyke Hüllermeier and Johannes Fürnkranz studied a particular instance of preference learning. They addressed this problem by reducing it to the learning by pairwise comparison paradigm. This allows to decompose a possibly complex prediction problem into learning problems of a simpler type, i.e., binary classification. Ming Li (University of Waterloo) received his PhD from Cornell University in 1985. His research interests cover a wide range of topics including bioinformatics algorithms and software, Kolmogorov complexity and its applications, analysis of algorithms, computational complexity, and computational learning theory. His outstanding contributions have been widely recognized. In 2006 he became an ACM fellow, a fellow of the Royal Society of Canada, and an IEEE fellow. Furthermore, he received the Award of Merit from the Federation of Chinese Canadian Professionals in 1997, the IEEE Pioneer Award for Granular Computing in 2006, the Premier's Discovery Award for Innovation Leadership in 2009, the Outstanding Contribution Award from IEEE for Granular Computing in 2010, and the Killam Prize in 2010. The invited talk Information Distance and Its Extensions by Ming Li presented two extensions to the general theory of information distance concerning multiple objects and irrelevant information. The theory of information distance emerged during the last two decades and it found numerous applications during the past ten years.
The paper Iterative Learning from Positive Data and Counters by Timo Kötzing considers the variation that an iterative learner has additionally access to a counter. While it was known that this additional information yields a strictly more powerful learning model, it remained open why and how such a counter augments the learner power. To answer this question, six different types of a counter are distinguished. In the previously studied case, the counter was incremented in each iteration, i.e., counting from zero to infinity (i.e., c(i+1) = c(i) + 1). Further possibilities include strictly increasing counters (i.e., c(i+1) > c(i)), and increasing and unbounded (i.e., c(i+1) ≥ c(i) and the limit inferior of the sequence of counter values is infinity). The paper completely characterizes the relative learning power of iterative learners in dependence on the counter type allowed. It is shown that strict monotonicity and unboundedness are the only properties of the counters that augment the learner power in the iterative setting. The situation changes if other learning criteria are considered. For example, the learner may be required to never abandon a correct hypothesis, or its hypotheses should not depend on the order and the number of repetitions of the examples. It is then shown that for each choice of two different counter types there is a learning criterion that, when augmented with one of the counter types, yields different learnable classes than the same criterion when augmented with the other counter type.
The setting studied by Sanjay Jain, Eric Martin, and Frank Stephan
in their paper Robust Learning of Automatic Classes of Languages
is different from the general one described above in that the classes
of target languages considered are required to be automatic ones.
That is, the authors consider classes of regular languages of the form
(Li)i ∈ I such
that {(i,x) | x ∈ Li } and I
itself are
regular sets. So automatic classes of languages are a particular type
of an automatic structure. Note that automatic structures
have received considerable attention recently in learning theory and elsewhere.
Furthermore, automatic classes are also a special case of indexed families
that have been intensively studied in learning theory.
To explain what is meant by robust learning, let us assume that
we know a class The paper Learning and Classifying by Sanjay Jain, Eric Martin, and Frank Stephan sheds additional light on our understanding of language learning by relating it to classification. The model of classification considered is new. The authors define a so-called P-classifier which takes as input a finite sequence of elements of a language L and a finite sequence of predicates from the set P. It then outputs either the special symbol ``?'' indicating that the classifier makes no guess or a finite sequence of truth values intended as guesses of the values of the predicates on the language L. A computable P-classifier M is said to classify a language L if for every text for L and for every finite sequence of predicates from P, the guesses of M are the correct truth values of the finite sequence of predicates on L for all but finitely many initial segments of the text. Again, a computable P-classifier is said to classify a class of languages if it classifies every language in the class. So it remains to specify the set P of allowed predicates. The basic predicates are membership of a particular element in L. The remaining predicates are Boolean combinations of these basic predicates. The paper then compares P-classification with different criteria of learning from text. These criteria are learning in the limit as described above, behaviorally correct learning and finite identification. Behaviorally correct learning differs from learning in the limit in that the learner has to output for all but finitely many inputs a correct hypothesis, but not necessarily the same one. Finite identification is a model, where it is demanded that convergence of the sequence of hypotheses is decidable. So the learner outputs again the special symbol `?'' indicating that it does not make a guess or a hypothesis. Once a hypothesis is output, it must be correct and learning is over. The main motivation for these investigations and the main insight obtained by these studies is the exploration of the idea that learning may be viewed as the limit of an increasing set of classification tasks. The paper Learning Relational Patterns by Michael Geilke and Sandra Zilles studies the learnability of a special target class. Patterns are a very intuitive way to define languages. A pattern is just a non-empty string over (Σ ∪ X), where Σ is finite alphabet (the so-called constants) and X = {x1, x2,… } is a countable set of variables. For example, ax1abbx2c x1 is a pattern provided a,b,c ∈ Σ. The language L(π) generated by a pattern π is the set of all strings obtainable by substituting strings over Σ for the variables occurring in π, where in each substitution step the same string has to be used for all occurrences of the same variable. So, abbabbaacbb ∈ L(π), where π = ax1abbx2cx1 and obtained by substituting bb for x1 and aa for x2. Note that it makes a huge difference whether or not only non-empty strings are allowed as substitutions. If this the case then the class of all pattern languages is learnable from text. On the other hand, if empty strings are allowed as substitutions then the class of all pattern languages is not learnable from text. The present paper considers the case that empty substitutions are not allowed. While the class of all such pattern languages is very interesting and has attracted a lot of attention, it may be also too general for several applications. Thus, the authors introduce a new class by allowing (a finite number of) relations between the variables in the pattern and call the new class relational patterns. For instance, a relation can be used to express the demand that the substitutions for the variables x1 and x2 used in one substitution step have always the same length (as in our example above). It is then shown that the class of relational pattern languages is learnable from text, where the hypotheses output are also relational patterns. The authors also study the complexity of the membership problem which is NP-complete for the original class. For relational patterns it is shown to be NP-hard. Finally, probabilistic relational patterns are considered. Now for each variable type (expressed by the given relations) a distribution over the set of allowed substitutions is specified. This induces a probability distribution over the strings of the language, and learning has to be performed with respect to all texts obtainable in this way. The success criterion is then relaxed to δ-learning, meaning that the learner has to succeed with probability at least 1 - δ. Under fairly natural conditions on a class of all relational patterns it is shown that δ-learning can be achieved.
Of considerable interest is to learn a linear mapping from a
d-dimensional Euclidean space to the set of real numbers, i.e., the
task of linear prediction.
In many practical problems one suspects that the weight
vector w∗
defining the linear mapping is sparse because not all inputs are
relevant. This also implies that the weight vector will have a small
1-norm. How to design algorithms that can exploit this prior
information has been the subject of intense investigation in recent
years. Sébastien Gerchinovitz and Jia Yuan Yu study this problem in
the online learning framework in their paper
Adaptive and Optimal Online Linear Regression
on l1-balls.
Their main contribution is showing that the best achievable regret is
subject to a phase transition depending on the value of the
``intrinsic quantity''
Nina Vaits and Koby Crammer in their paper Re-Adapting the Regularization of Weights for Non-Stationary Regression consider the problem of tracking the best sequence of weights also in the context of linear prediction with a squared loss. They develop an algorithm which uses per-feature learning rates and prove a regret bound with respect to the best sequence of functions. Under some technical assumption and with proper tuning, the regret is shown to be of order O(T (p + 1)/2p log T) when the best weight sequence's ``cumulative deviation'' is of order O(T 1/p) for some p > 1. They also show that by running multiple instances in parallel, prior knowledge of p can be avoided. Oftentimes, analyzing the ``in-sample'' or training error is the first step in the analysis of the risk of regression methods. Moreover, the behavior of the training error is also of major interest in signal or image processing when the goal of learning is to reject noise at the input points in the training data. The main novelty in the paper of Arnak S. Dalalyan and Joseph Salmon (Competing Against the Best Nearest Neighbor Filter in Regression) is that the authors prove a sharp oracle inequality for the expected training error of a procedure that they suggest. The oracle inequality is called sharp as its leading constant, multiplying the risk of the best predictor within the considered set of predictors, is one and the additive residual term decays at the rate of O(1/n). The procedure itself uses aggregation with exponential weights over a set of symmetrized linear estimators, a special case of which are nearest neighbor filters. In particular, the procedure avoids the need to choose the number of neighbors k to be considered and yet its performance is guaranteed to be almost as good as that of the nearest neighbor filter with the best choice of k. The procedure assumes the knowledge of the covariance matrix underlying the noise or an unbiased estimate of this covariance matrix which is independent of the responses used in the training procedure.
In their paper {Lipschitz Bandits without the Lipschitz Constant Sébastien Bubeck, Gilles Stoltz, and Jia Yuan Yu study bandit problems when the set of actions is the d-dimensional hypercube and the payoff function is known to be globally Lipschitz with respect to the maximum-norm. They develop an algorithm which works as well as the Lipschitz constant was available though their algorithm does not need to know the Lipschitz constant. This is in contrast to previous works which either assumed that the Lipschitz constant is known \emph{a priori} or the regret of the algorithm scaled suboptimally as a function of the unknown Lipschitz constant. The strategy proposed is based on a discretization argument, assumes the knowledge of the horizon and proceeds in two phases. In the first phase, the Lipschitz constant is estimated by exploring the points in the hypercube uniformly. By the end of this phase, the Lipschitz constant is estimated based on the obtained data. By biasing the estimate obtained this way upwards, it is ensured that the the Lipschitz constant will not be underestimated. In the second phase, the hypercube is discretized based on the estimated biased Lipschitz constant and then a standard multi-armed bandit strategy is used in the resulting finite-armed problem. Most papers concerned with the stochastic version of bandit problem study the expected regret. However, a decision maker might also be interested in the risk, i.e., whether the regret is small not only in expectation, but also with high probability. In their paper Deviations of Stochastic Bandit Regret Antoine Salomon and Jean-Yves Audibert show that in the classical setting of finite-armed stochastic bandit problems whether ``small risk'' policies exist hinges upon whether the total number of plays is known beforehand. That small risk is possible to achieve when this knowledge is available was known beforehand. The new result is that without this knowledge, no algorithm can achieve small risk except when the class of distributions that can be assigned to the actions is restricted in some way.
Bandit algorithms designed for static environments are not expected to
work well when the environment changes from time to time, for example when
the environment changes abruptly.
In the case of adversarial stochastic bandits, the corresponding
problem is called the tracking problem and the so-called Exp3.S
algorithm was shown to achieve a regret of
Online learning with bandit information can be studied under various criteria. In their paper Upper-Confidence-Bound Algorithms for Active Learning in Multi-Armed Bandits Alexandra Carpentier, Alessandro Lazaric, Mohammad Ghavamzadeh, Rémi Munos, and Peter Auer study the problem of estimating the mean values of a a finite number of actions uniformly well. In earlier work, a specific algorithm based on a forced exploration strategy was designed and analyzed for this problem. However, it is suspected that forced exploration with a fixed exploration rate can lead to suboptimal performance. In their paper Carpentier et al. study algorithms which avoid fixed rate forced exploration schemes. The performance bounds developed are indeed better than that of developed for the forced exploration scheme.
The classical perceptron algorithm takes very little time per iteration and is guaranteed to find a hyperplane separating the positive and negative data points if one exists, but the margin of the hyperplane is not in any way optimized. Various algorithms for optimizing the margin are known, but they get computationally quite demanding for large data sets. Constantinos Panagiotakopoulos and Petroula Tsampouka in their paper The Perceptron with Dynamic Margin contribute to the line of research that tries to combine the computational simplicity of the perceptron algorithm with guaranteed approximation bounds for the margin. The algorithm is based on maintaining a dynamic upper bound on the maximum margin. Besides the theoretical approximation bound, also experiments show the algorithm to perform well compared to previous ones for the same problem. The paper Combining Initial Segments of Lists by Manfred K. Warmuth, Wouter M. Koolen, and David P. Helmbold falls broadly within the framework of predicting with expert advice. As an example, suppose you have K different policies for maintaining a memory cache of size N. Different policies work well for different access sequences, and you would like to combine the caches of the K policies dynamically into your own cache of size N such that no matter what the access sequence, you do not incur many more misses than the best of the K policies for that particular sequence. A naive implementation of the well-known Hedge algorithm for predicting with expert advice is not computationally feasible, since there are roughly N K ways of picking your combined cache. However, the paper comes up with efficient algorithms based on the special combinatorial structure of this set of N K combinations. Also some lower bounds and hardness results are presented. The paper Regret Minimization Algorithms for Pricing Lookback Options by Eyal Gofer and Yishay Mansour applies tools from online prediction to finance. The final goal of the paper is to get upper bounds for the values of a certain type of an option. Assuming an arbitrage-free market, such upper bounds can be derived from regret bounds for trading algorithms. The trading algorithm considered here combines one-way trading (selling stock over time but never buying more) with regret minimization that tries to follow which performs better, cash or stock. A simulation on real stock data demonstrates how the bound works in practice. The paper Making Online Decisions with Bounded Memory by Chi-Jen Lu and Wei-Fu Lu is concerned with the problem of prediction with expert advice for 0-1 losses when the predictor is a finite state machine. Assuming that the number of actions is n, it is shown that any predictor with mn - 1 states must have regret Ω(T /m) in T time steps (note that remembering the exact number of mistakes of each expert would use Tn states). In the paper the authors propose two new algorithms for this problem: the first one is based on exponential weighting and achieves O(m + T /m ln(nm)) regret (for small m), while the second algorithm, based on gradient descent, achieves O(n√m + T / √m) regret. Note that the first algorithm achieves an almost optimal √(T ln n) regret using roughly half the memory that standard algorithms would use. In sequence prediction the problem is to predict the next symbol of a sequence given the past. As it is well known Solomonoff induction solves this problem, but only if the entire sequence is sampled from a computable distribution. In the paper Universal Prediction of Selected Bits Tor Lattimore, Marcus Hutter, and Vaibhav Gavane consider the more general problem of predicting only parts of a sequence, lifting the restriction that the sequence is computable (or sampled from a computable distribution). For example, in an online classification problem, the side information available to predict the next outcome can be arbitrary, the only part that needs to be predicted are the labels. They show that the normalized version of Solomonoff induction can still be used in this more general problem, and in fact it can detect any recursive sub-pattern (regularity) within an otherwise completely unstructured sequence. It is also shown that the unnormalized version can fail to predict very simple recursive sub-patterns. Consider two computers communicating using protocols designed and implemented by different parties. In such settings, the possibility of incompatibility arises. Thus, it is desirable if one (or both) computers utilize a communication strategy that automatically corrects mistakes. Previous work has shown that if the user can sense progress, such a strategy exists if there exists a protocol at all that would achieve the goal of communication. The drawback of the actual constructions is that they rely on enumerating protocols until a successful one is discovered, leading to the potential for exponential overhead in the length of the desired protocol. Brendan Juba and Santosh Vempala in their paper Semantic Communication for Simple Goals is Equivalent to On-line Learning consider the problem of reducing this overhead for some reasonably general special cases. Most interestingly, this is done by establishing an equivalence between these special cases and the usual model of mistake-bounded on-line learning. The results motivate the study of sensing with richer kinds of feedback.
The paper Accelerated Training of Max-Margin Markov Networks with Kernels by Xinhua Zhang, Ankan Saha, and S.V.N. Viswanathan considers structured output prediction, where in addition to the inputs, also the outputs to be predicted can have a complicated structure. Using the kernel paradigm this can be modeled assuming a joined feature map φ that maps input-output pairs (x,y) into the feature space. One way of proceeding from there, and the one adopted in this paper, is max-margin Markov networks, which leads to a minimization problem where the objective function is convex but not smooth. Non-smoothness rules out some of the faster optimization methods. This paper shows how some known techniques for this kind of optimization can be modified so that they retain their convergence speed, getting to within ε of the optimum in O(1/√ε) iterations, and allow the iteration step to be implemented in an efficient manner that utilizes the structure of the outputs. Corinna Cortes and Mehryar Mohri in their paper Domain Adaptation in Regression consider the situation when the training and test data come from different distributions. We assume there is little or no labeled data about the target domain where we actually wish to learn, but unlabeled data is available, as well as labeled data from a different but somehow related source domain. Previous work has introduced a notion of discrepancy such that a small discrepancy between the source and target domains allows learning in this scenario. This paper sharpens and simplifies the previous results for a large class of domains related to kernel regression. It then goes on to develop an algorithm for finding a source distribution that minimizes the discrepancy and shows empirically that the new algorithm allows domain adaptation on much larger data sets than previous methods. The paper Approximate Reduction from AUC Maximization to 1-Norm Soft Margin Optimization by Daiki Suehiro, Kohei Hatano, and Eiji Takimoto considers the problem of obtaining a good ranking function as a convex combination of a given set of basic ranking functions. Area under the ROC curve (AUC) is a popular performance measure for ranking, and known results bounds it in terms of a margin-based criterion for pairs of positive and negative examples. However, using this reduction directly to optimize AUC leads to a problem of size O(pn), where p is the number of positive examples and n the number of negative examples in the original problem. This is computationally infeasible for even moderately large data sets. The paper presents an alternative reduction that leads to a problem of size O(p + n). The problem thus obtained is not equivalent with the original problem, but the paper provides some approximation guarantees, and shows empirically that the proposed approach is practical.
In their paper Axioms for Rational Reinforcement Learning, following Savage's pioneering work, Peter Sunehag and Marcus Hutter define a notion of rational agents and show that the so-defined rational agents act as if they maintained a probabilistic world model. The simplest rationality concept considered in the paper from which the other concepts are derived concerns agents who have preferences above payoff schemes corresponding to a single uncertain outcome. The authors also investigate the subtleties of countably infinite outcomes and asymptotic optimality when an agent faces countably many environments. Laurent Orseau studies the question of how to design agents which are ``knowledge seeking'' in the paper titled \papertitle{Universal Knowledge-Seeking Agents}. The knowledge-seeking agents are those who have a probabilistic world model. In a rather unorthodox manner, the immediate cost suffered by such an agent at some time step is defined as the conditional probability assigned to future outcomes based on the probabilistic world model that the agent chose to use. Arguably, an agent that uses an appropriate world model and that acts so as to minimize the long-term cost will choose actions that allow it to ``discard'' as many environments as quickly as possible. Performance is compared to the expected total cost suffered by the optimal agent that uses the probability distribution of the true environment as its world model. The main result, which is proven for certain ``horizon functions,'' shows that the so-called AIXI agent's performance converges to the optimal performance provided that the environment is deterministic. A cost defined using the logarithm of the conditional probabilities, i.e., a Shannon-type cost, is also studied. A recent result by Orseau published at ALT 2010 showed that Hutter's universal Bayesian agent AIXI fails to be weakly asymptotically optimal when the environment is chosen to be some computable deterministic environment. The main observation in the paper Asymptotically Optimal Agents by Tor Lattimore and Marcus Hutter is that a similar result holds true for arbitrary agents. In particular, the authors study this question in general discounted deterministic reinforcement problems. It is shown that no learning algorithm can be strongly asymptotically optimal for this class of environments, while the existence of weakly asymptotically optimal algorithms depends on the considered discount function. However, weakly asymptotically optimal algorithms are necessarily incomputable. One such algorithm is presented for geometric discounting. A discount matrix d is an ∞ × ∞ matrix: At time step t an agent using d would ``discount'' future rewards using the values in the tth column of d. A discount matrix leads to time-consistent behavior if for any environment the optimal policy given some history up to time t uses the same action as the optimal policy that is computed with a column of the discount matrix corresponding to some previous time instance (ties are assumed to be broken in an arbitrary, systematic manner). Tor Lattimore and Marcus Hutter prove a characterization of what discount matrices lead to time consistent discounting in their paper Time Consistent Discounting. They also study the sensitivity of behaviors to perturbations of a time-consistent discount matrix. Finally, using a game theoretic approach, they show that there is a rational policy even if the discount matrix is time-inconsistent.
Probably approximately correct (PAC) learning is another model that has served as the framework for many fundamental results and also inspired a large number of other models. In the basic PAC setting, the unknown quantities are a target concept ƒ : X → {0,1} and a probability measure P over X. The learner receives a set of labeled examples (x,ƒ(x)) and outputs a hypothesis h: → {0,1}. For given ε and δ, the hypothesis must satisfy with probability at least 1 - δ the property P(ƒ(x) &ne h(x)) ≤ ε. The analysis of a learning algorithm involves estimating the required number of examples and the computation time in terms of ε, δ and other relevant parameters of the problem.
The paper Distributional Learning of Simple Context-Free
Tree Grammars by Anna Kasprzik and Ryo Yoshinaka considers learning
of languages consisting of trees, not strings.
Context-free tree grammars generalize the notion of context-free grammars
from strings to trees.
While learning general context-free languages seems difficult, efficient
learning algorithms for several subclasses are know.
The present paper, in particular, takes as a starting point the known
results for substitutable context-free languages.
A context-free language L over is substitutable, if any two
strings z1 and z2
that satisfy uz1v ∈ L and
Co-training under the conditional independence assumption is a model
often used in PAC-style analysis of semisupervised learning. In this
model, access to a large number of unlabeled examples can lead to a
drastic reduction in the required number of labeled examples.
The paper Supervised Learning and Co-Training by
Malte Darnstädt, Hans Ulrich Simon, and Balázs Szörényi
poses the question of how much of this reduction is due to the unlabeled
examples, and how much would result from the conditional independence
assumption even without access to any unlabeled examples.
It turns out that under this assumption, the number of labeled
examples needed to co-train two concept classes, having VC-dimensions
d1 and d2, is
A labeled random example (x,ƒ(x)) gives information both about the target function ƒ and the distribution of x. The paper Learning a Classifier When the Labeling is Known by Shalev Ben-David and Shai Ben-David focuses on the second aspect by assuming that the target function ƒ is actually known to the learner beforehand. The learning problem is still nontrivial if we require that the hypothesis h belongs to some restricted hypothesis class H that does not include the target ƒ. In practice, such restrictions might arise because the hypothesis must be very efficient to evaluate, or in a form understandable to a human expert. The paper establishes a combinatorial property of H based on shattering that tells us which of three cases holds: the required number of samples is either zero, Θ(1/ε), or Ω(1/ε2).
©Copyright Notice:
|
 back to
the ALT 2011 Proceedings Page
back to
the ALT 2011 Proceedings Page
![]()
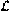 to be learnable. The interesting
question is then what can be said about the classes
to be learnable. The interesting
question is then what can be said about the classes 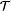 that are obtainable by applying an algorithmic transformation to
that are obtainable by applying an algorithmic transformation to 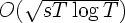 on a horizon T when the number of abrupt changes is at most s.
Aurélien Garivier and Eric Moulines study the same problem in a
stochastic setting.
In their paper titled On Upper-Confidence Bound Policies
for Switching Bandit Problems
they prove that already when a single switch between two stochastic
environments
on a horizon T when the number of abrupt changes is at most s.
Aurélien Garivier and Eric Moulines study the same problem in a
stochastic setting.
In their paper titled On Upper-Confidence Bound Policies
for Switching Bandit Problems
they prove that already when a single switch between two stochastic
environments
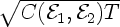 regret,
where
regret,
where
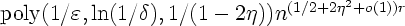 , which is the first known improvement over
the brute-force bound O(nr).
The results of this paper can be combined with earlier work to get
bounds for general r-juntas (functions that depend on only r input
bits) and for s-term DNF formulas.
, which is the first known improvement over
the brute-force bound O(nr).
The results of this paper can be combined with earlier work to get
bounds for general r-juntas (functions that depend on only r input
bits) and for s-term DNF formulas.
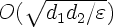 .
For small ε this is significantly smaller than the
lower bound Ω(d /ε) for learning a concept class
of VC-dimension d without the conditional independence assumption.
.
For small ε this is significantly smaller than the
lower bound Ω(d /ε) for learning a concept class
of VC-dimension d without the conditional independence assumption.