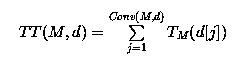| ALT | Page 1 |
|
Complexity of LearningLet LIMm denote the collection of all concepts classes that can be learned by an IIM M that makes on every data sequence for every concept at most m mind changes. Then, the following theorem can be proved for every infinite learning domain. Theorem 1. LIM0 ⊂ LIM1 ⊂ LIM2⊂ ... ⊂ LIMk ⊂ LIMk+1 ⊂ ... Clearly, Theorem 1 provides evidence that the number of mind changes is reflecting at least some aspects of the complexity of learning in the limit. Nevertheless, this complexity measure says almost nothing about the total amount of data and/or resources needed until successful learning. Therefore, further complexity measures have been introduced. Next, we define the update time and the total learning time. Let C be any concept class, c ∈ C be any concept, and let d be any data sequence for c. We define Conv(M,d) = df the least number i such that
to be the stage of convergence of M on d Moreover, by TM(d[j]) we denote the number of steps to compute M(d[j]). We measure this quantity as a function of the length of the input and refer to it as the update time. At first glance, it may seem that the update time is really an appropriate complexity measure for learning in the limit. There are, however, several problems with this complexity measure. First of all, one can always achieve a linear update time by applying a simple simulation technique. The price paid is generally an increase of the stage of convergence. Since this is clearly not desired, many authors put additional constraints to all hypotheses produced. A very common requirement is consistency. A learner M is said to be consistent provided every hypothesis correctly reflects all the data seen so far. More precisely, if d[j] is the actual initial segment, then a consistent hypothesis must contain all examples labeled 1 and none of the examples labeled 0 (in the informant case). If learning from text is considered then a consistent hypothesis must contain all the data present in d[j]. Although the requirement to learn consistently looks reasonable at first glance, it should be noted that it may lead to the unsolvability of the whole learning problem or it may result in a non-feasible update time. For further information concerning this subject, the reader is referred to our article on Learning and Consistency. Besides that, the update time alone does not provide any information concerning the total amount of time needed until successful learning. This information is only provided by the total learning time which we thus define next. The total learning time TT(M,d) taken by the learner M on successive input of a data sequence d is the sum of all update times until convergence, i.e.,
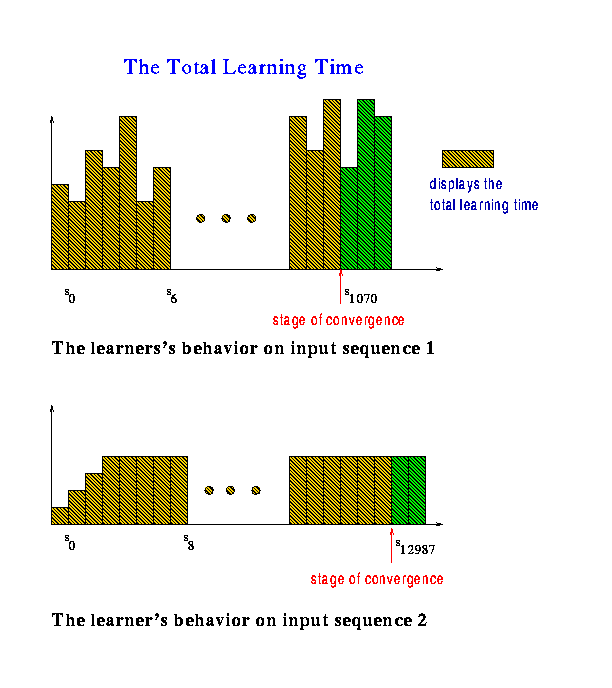
The figure below displays the total learning time of one and the same learner M on different data sequences. Still, there is a problem. What one usually likes to have is a learner that has a polynomial total learning time. This could be easily said, however, we have to specify what is really meant, i.e., polynomial in what? Thus, the crucial point is the right definition of the problem size? If one takes the sum of the length of all elements seen until convergence (and possibly the length of target concept as additional parameter) then a learner could simply delay convergence until sufficiently long examples have been appeared. On the other hand, if we take the length of the shortest hypothesis describing the target concept as problem size then the total learning time is usually unbounded in the worst-case. This is caused by the fact that the learner has to learn from all data sequences. Thus, taking a data sequence containing as many repetitions as necessary of elements that do not suffice to learn the target, every bound can be exceeded. See for example the learner's behavior on input sequence 2 below. On the other hand, such worst-case data sequences may be rare in practice if they occur at all. Consequently, in order to arrive at a complexity measure that has much more practical value than a worst-case analysis, one has to study the average-case behavior of a learner.
|