
| ALT | Page 5 |
|
In the setting of on-line prediction the source of information
is specified as follows. The learner will
be fed successively more and more labeled examples of the monomial
to be learned. That is, the learner is given a sequence
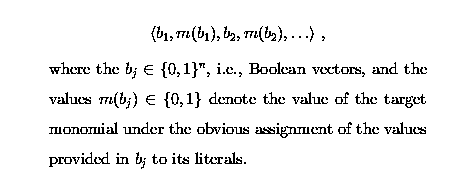
The examples are picked up arbitrarily, and are noise free. We do not specify the hypothesis space explicitly. It is left to the learner to choose it. Finally, we have to specify the criterion of success. In this example, we consider on-line prediction (cf. [1,3]). That is, the learner must predict each m(b), after having been fed b. Then, it receives the true value of m(b), and the next Boolean vector. If the learners prediction differs from the true value c(b) then a prediction error occurred. We measure the performance of the learner by the number of prediction errors made. The learner has successfully learned if it eventually reaches a point beyond which it always correctly predicts. Obviously, there is a trivial solution. The learner simply keeps track of all examples and their labels provided. If it is fed a vector b the label of which it has already seen, it predicts the correct label. Otherwise, it predicts 0. After having seen all possible examples, it surely can correctly predict. However, there are 2 to the power of n Boolean vectors of length n. As a consequence, this trivial algorithm may make many exponentially prediction errors. Thus, for any n of practical relevance, it may take centuries before before the algorithm has achieved its learning goal. Clearly, this is not acceptable. Hence, we continue by asking whether we can do it better. The affirmative answer is provided by the following theorem.
Theorem 1. On-line prediction of monomials over
Proof. The main ingredient to this proof is the so-called Wholist algorithm (cf. Haussler [2]) which we thus present next.
You may want to try this algorithm out to get a better understanding of how it works. For that purpose, you may use our Applet. Alternatively, you may want to see our animation first.
References
[1] J.M. Barzdin and R.V. Freivald,
On the prediction of general recursive functions.
Soviet Math. Doklady 13:1224-1228, 1972.
Continue to the Lerning in the Limit page. |
![]()
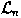 can be done with at most n+1 prediction mistakes.
can be done with at most n+1 prediction mistakes.
