A Fast Algorithm for Discovering Optimal String Patterns in Large Text Databases
Authors: Hiroki Arimura, Atsushi Wataki, Ryoichi Fujino, and Setsuo Arikawa
Source: Lecture Notes in Artificial Intelligence Vol. 1501, 1998, 247 - 261.
Abstract. We consider a data mining problem in a large collection of unstructured texts based on association rules over subwords of texts. A two-words association pattern is an expression such as
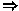 C
C
that expresses a rule that if a text contains a subword TATA
followed by another subword AGGAGGT with distance no more than
30 letters then a property C will hold with high probability.
The optimized confidence pattern problem is to compute frequent
patterns (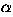 , k,
, k, 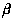 ) that optimize the confidence with
respect to a given collection of texts. Although this problem is
solved in polynomial time by a straightforward algorithm that
enumerates all the possible patterns in time O(n5 ),
we focus on the
development of more efficient algorithms that can be applied to large
text databases.
We present an algorithm that solves the optimized
confidence pattern problem in time O(max{k,m}n2 )
and space O(kn),
where m and n are the number and the total length of
classification examples, respectively, and k is a small constant
around 30 ~ 50.
This algorithm combines the suffix tree data structure in
combinatorial string matching and the orthogonal range query technique
in computational geometry for fast computation.
Furthermore for most random texts like DNA sequences, we show that a
modification of the algorithm runs very efficiently in time
O(kn log3 n) and space O(kn).
We also discuss some heuristics such as sampling and pruning as
practical improvement. Then, we evaluate the efficiency and the
performance of the algorithm with experiments on genetic sequences. A
relationship with efficient Agnostic PAC-learning is also discussed.
) that optimize the confidence with
respect to a given collection of texts. Although this problem is
solved in polynomial time by a straightforward algorithm that
enumerates all the possible patterns in time O(n5 ),
we focus on the
development of more efficient algorithms that can be applied to large
text databases.
We present an algorithm that solves the optimized
confidence pattern problem in time O(max{k,m}n2 )
and space O(kn),
where m and n are the number and the total length of
classification examples, respectively, and k is a small constant
around 30 ~ 50.
This algorithm combines the suffix tree data structure in
combinatorial string matching and the orthogonal range query technique
in computational geometry for fast computation.
Furthermore for most random texts like DNA sequences, we show that a
modification of the algorithm runs very efficiently in time
O(kn log3 n) and space O(kn).
We also discuss some heuristics such as sampling and pruning as
practical improvement. Then, we evaluate the efficiency and the
performance of the algorithm with experiments on genetic sequences. A
relationship with efficient Agnostic PAC-learning is also discussed.
©Copyright 1998 Springer