Skip to content
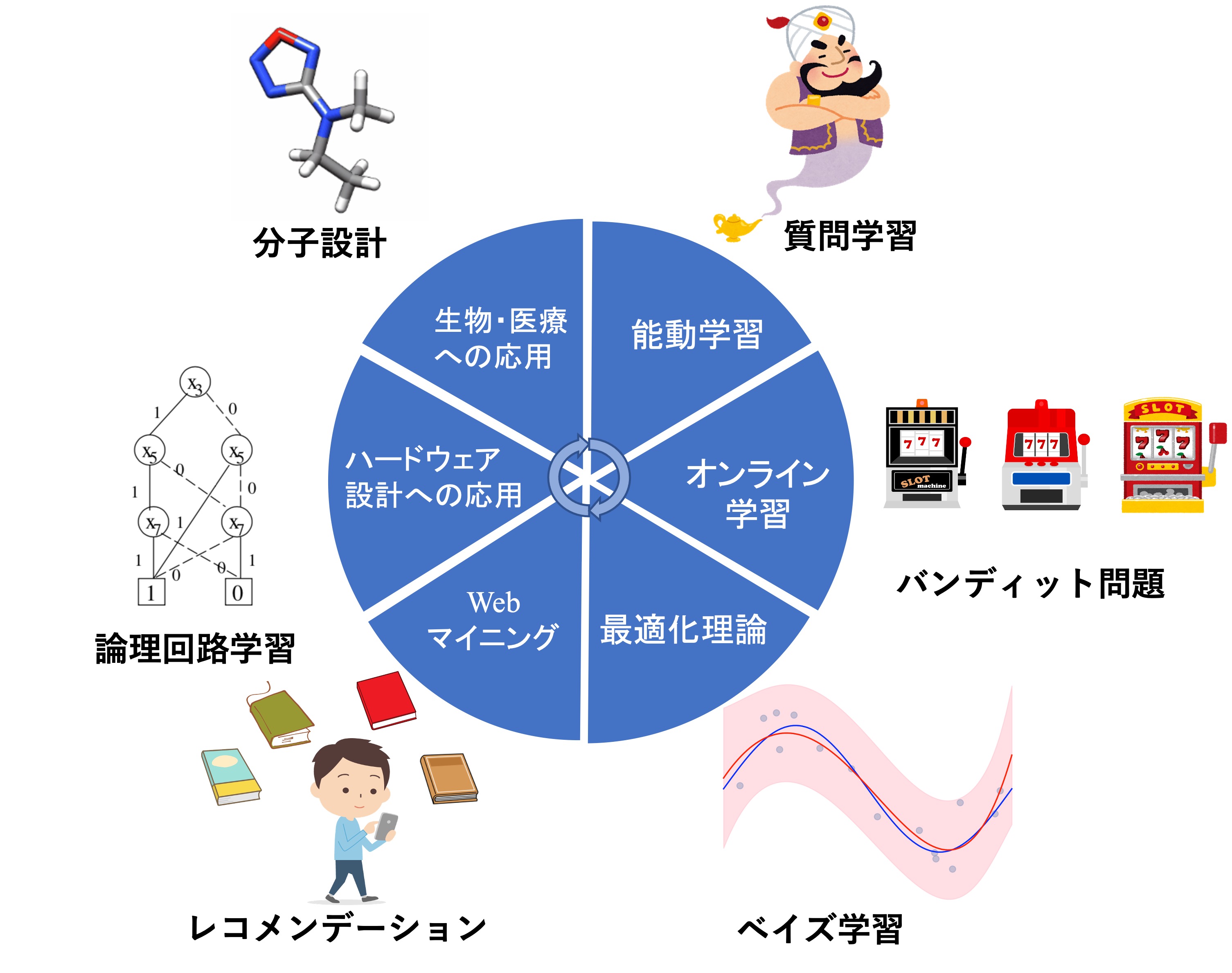
機械学習の理論研究
オンライン学習
我々は、行動及びそれに対する評価のフィードバックを受ける、ということを繰り返し、累積評価値が最大になる行動を選ぶように生きていると考えることができます(それだけではありませんが(^^;;))。このように過去の行動履歴とそれに対する損益を基に次の行動を決めることを繰り返し、累積利得の最大化(累積損失の最小化)を目的として行動の最適化を行う学習をオンライン学習と言います。ネットを介してユーザの行動を即座に知ることができる現在では、ユーザの行動に対し、システムが最適なサービスを提供するためにはこのオンライン学習の技術が欠かせません。得られる情報の制約や、最大(最小)化する目的関数など、現実の問題を定式化した異なる設定で性能保証のあるアルゴリズムの開発や、性能の限界について研究します。
バンディット問題で遊ぼう!
能動学習
アキネイターというあなたが考えていることを当てる魔神がいるのをご存知でしょうか。アキネイターはいくつかあなたに質問をしてあなたの考えている有名な人物やキャラクターを少ない質問で当ててしまいます。何故アキネイターはあなたの考えていることを少ない質問で当てることができるのでしょうか。能動学習とは、少ない質問で当てるために、何を質問しなければならないかを追求する理論であるといえます。ある関数を学習するのに、機械学習ではある分布に従って発生したデータをもらって学習する枠組み(受動学習)が一般的ですが、能動学習はその時点で精度上げるために必要なデータを逐次的に取得するので、少ないデータでの学習が可能になります。昔から行われている実験計画法や、ベイズ推定を用いる方法、計算論的学習理論における質問学習などの研究があります。
機械学習の応用研究
Webマイニング
インターネットの発達により、人の行動履歴やセンサー情報など、様々な情報がWebを介して瞬時に得られるようになってきました。それらの情報を学習し、その人に合った広告を出したり、商品を推薦したり、または不正検出をするなどの技術の開発が進んでいます。 そこで活躍する学習技術が、オンライン学習と能動学習です。オンライン学習を用いれば、逐次得られるデータを使って仮説を目的に合うように更新したり、変化する好みや傾向に対応するシステムを構築することが可能になります。また、推薦システムなどで新規ユーザに対するお勧め精度が悪い問題などでは、能動学習を用いて精度を上げることができます。Webシステムはユーザ数も多くなることから、高速なアルゴリズムの開発も重要になります。
ハードウェア設計への応用
現在は空前の機械学習ブームで機械学習の需要が非常に大きくなっています。しかし、深層学習など、機械学習は多くの計算リソースを必要とするため、高性能なマシンを用意する必要があります。しかしそれではコストがかかり、また計算リソースが少ないエッジデバイスでは利用できません。限られたハードウェア資源で動作するコンパクトな識別器や予測器を学習する技術や、制限されたハードウェアで実現できる学習器やアダプティブな予測器の開発を行なっています。
生物・医療への応用
オンライン学習問題であるバンディット問題の解法アルゴリズムを用いて、ラマン分光による癌診断を高速化する研究、パターンマイニングを用いてDNAシーケンスの反復配列を抽出する研究などを行なっています。
ラマン分光はレーザを物質に照射することにより物質から散乱する光であり、分子構造の違いにより得られる光が異なるため、癌細胞と正常細胞をラマン分光から区別することが可能だと言われています。癌診断は細胞の形状から行われるものが多いですが、癌によっては甲状腺濾胞癌のように細胞の形状からの診断が難しいものもあります。そのような癌にはラマン分光による診断は有効と考えられていますが、ラマン分光は弱く計測に時間がかかり、一度に2次元的な計測を行うことが難しいため、1つの試料の測定に何度も位置を変えて測定しなければならず、計測に時間がかかります。そこで計測領域をグリットに分割し、がん細胞を含むグリットが存在するか否かを判定する問題をバンディット問題として定式化し解くことにより、より速い診断を可能にする研究を北大電子研小松崎教授グループと共同で行なっています。
ヒトのDNAシーケンスの半分は反復配列(タンデムリピートと散在反復配列)だと言われており、それらは生物の進化に関係していると言われています。反復配列の全容解明のために、事前知識を用いた方法などにより多くの反復配列が発見されデータベース化されてきました。本研究室では、文字列マイニングの技術を用いて反復配列の全抽出に取り組んでいます。反復配列を文字列パターンの出現とみなし、統計的に有意に出現する文字列パターンを全て求める方法を開発し、色々な方法で発見された既知の反復配列の87.5%を抽出することに成功しています。